Disparity Estimation Using a Quad-Pixel Sensor
BMVC 2024
BMVC Project Page with Poster and VideoZhuofeng Wu1, Doehyung Lee1, Zihua Liu1,
Kazunori Yoshizaki2, Yusuke Monno1, Masatoshi Okutomi1
Tokyo, Japan
Tokyo, Japan
Abstract
A quad-pixel (QP) sensor is increasingly integrated into commercial mobile cameras. The QP sensor has a unit of 2×2 four photodiodes under a single microlens, generating multi-directional phase shifting when out-focus blurs occur. Similar to a dual-pixel (DP) sensor, the phase shifting can be regarded as stereo disparity and utilized for depth estimation. Based on this, we propose a QP disparity estimation network (QPDNet), which exploits abundant QP information by fusing vertical and horizontal stereo-matching correlations for effective disparity estimation. We also present a synthetic pipeline to generate a training dataset from an existing RGB-Depth dataset. Experimental results demonstrate that our QPDNet outperforms state-of-the-art stereo and DP methods.
Method Overview
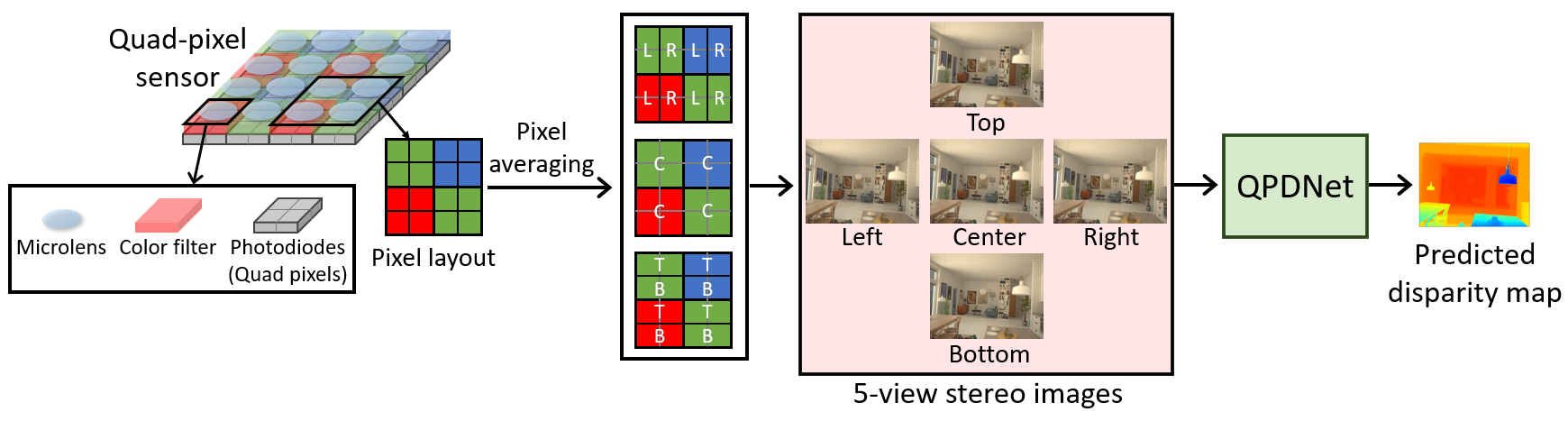
We first apply three kinds of pixel averaging of raw pixel values and generate five-view (i.e., left, right, center, top, and bottom) stereo images, where the center image is used as a reference to integrate two horizontal (center-right and center-left) and two vertical (center-top and center-bottom) disparity information.
Subsequently, we propose a QP disparity estimation network (QPDNet), which effectively utilizes multi-directional disparities observed using a QP sensor.
QP Disparity Estimation Dataset Generation
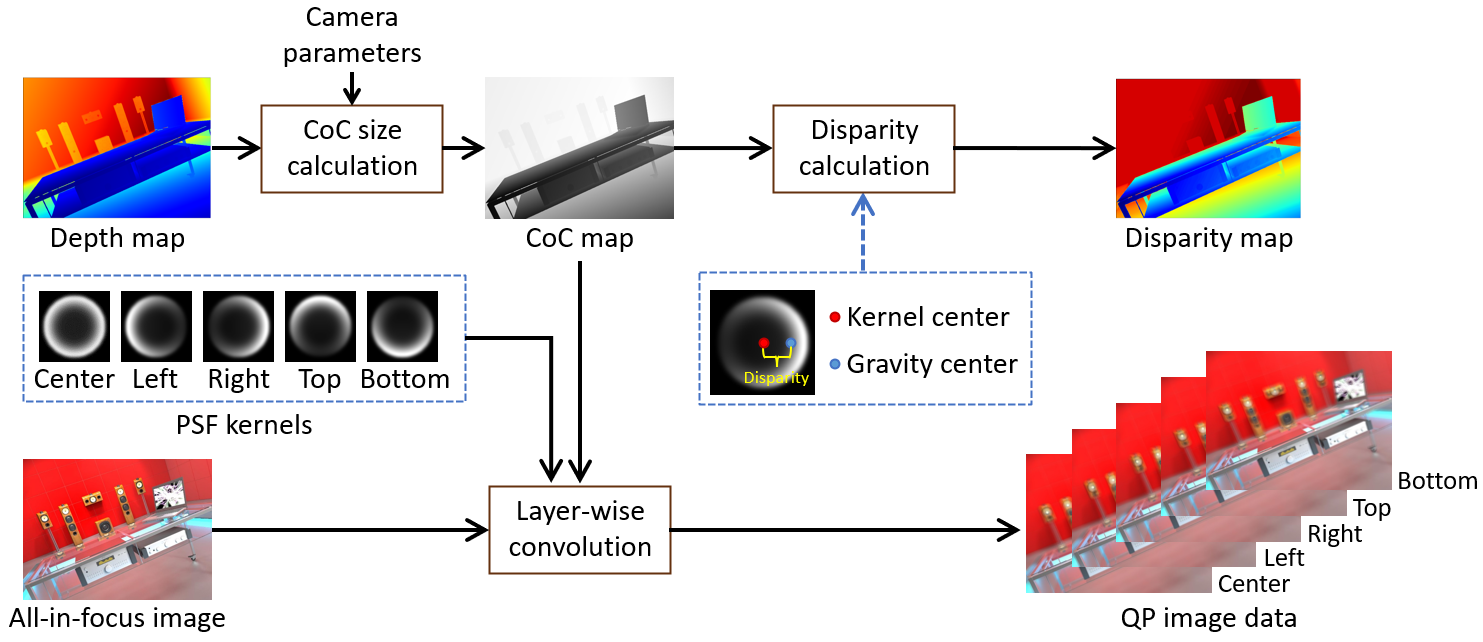
We rebuild a synthetic pipeline to generate a QP image based on the DP image generator and used the existing RGB-D datasets [Hypersim] for generation.
The top and the bottom images are generated by rotating the DP left and right PSF kernel and the PSF for the center image is also generated by averaging the left and the right kernels.
Proposed QPDNet
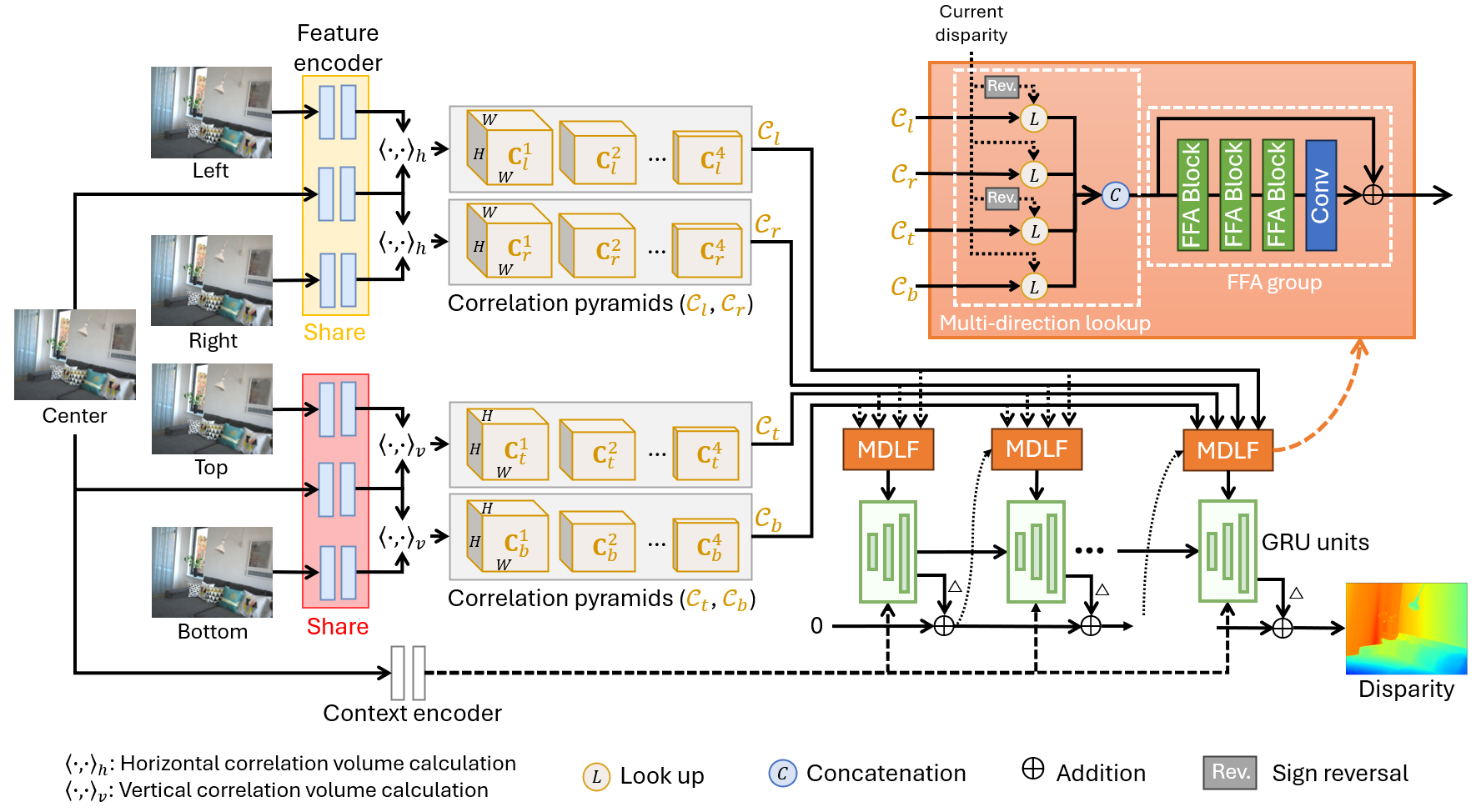
Inspired by the success of RAFT-Stereo, we propose to construct four-directional correlation pyramids and effectively fuse them by introducing a novel multi-direction lookup fusion (MDLF) module, which is designed to extract local correlations in multiple directions and to enable adaptive fusion of extracted correlations by utilizing both channel-wise and pixel-wise attention mechanisms.
Evaluation Results
The quantitative comparisons on the synthetic dataset with Gaussian noise
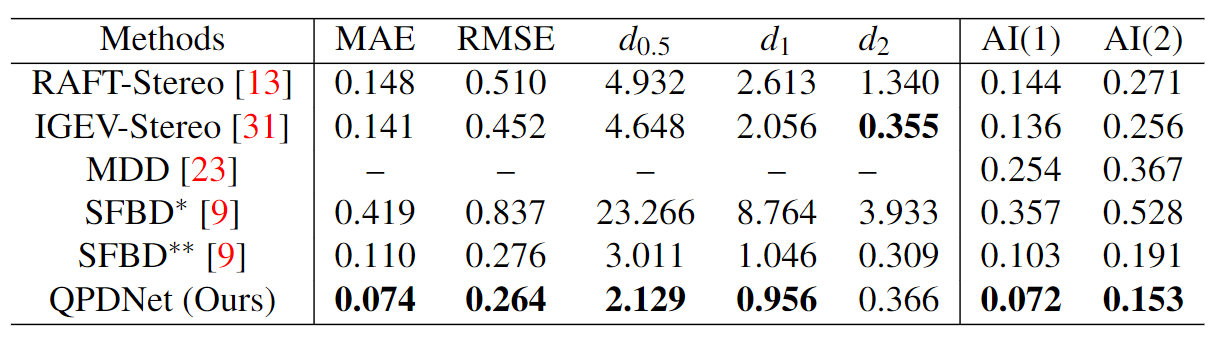
SFBD* indicates the utilization of pre-trained weights, while SFBD** refers to the model that was trained on our training data in a supervised manner.
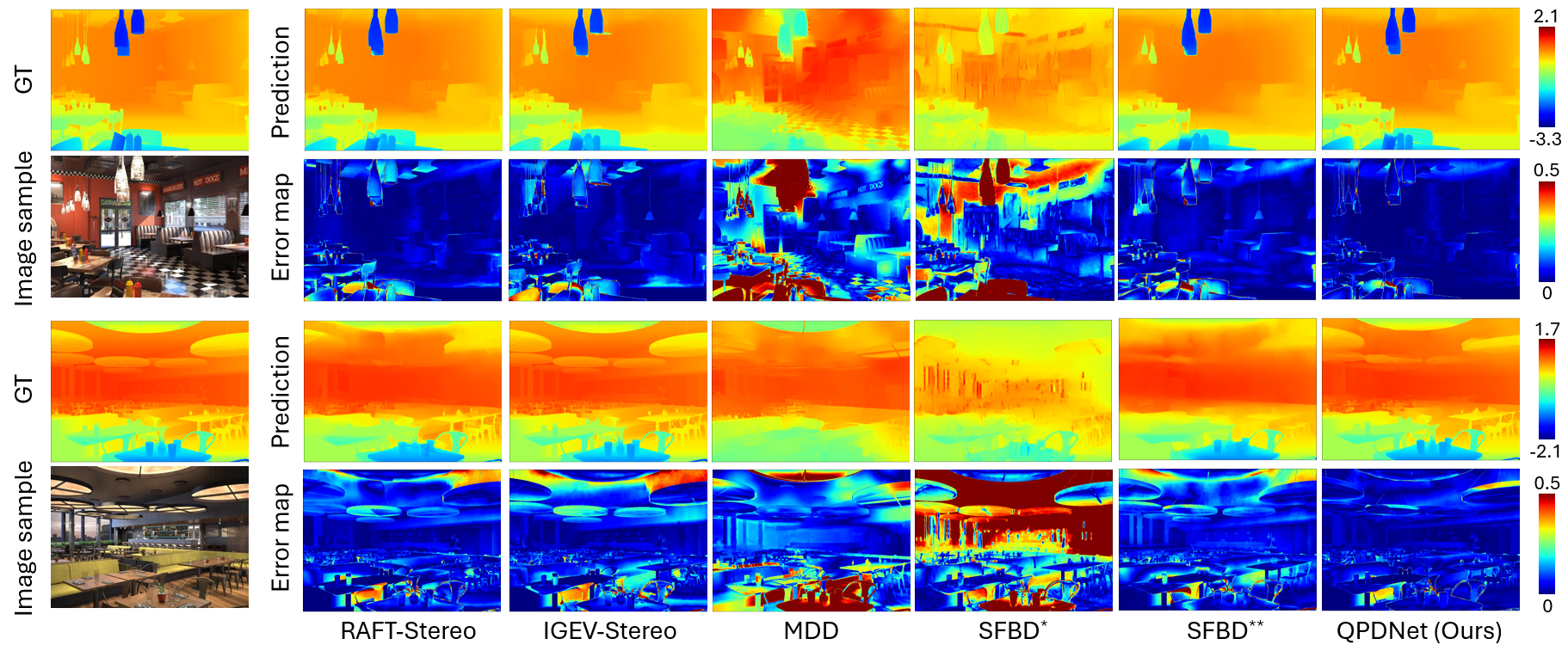
Visual comparisons on the synthetic data with Gaussian noise
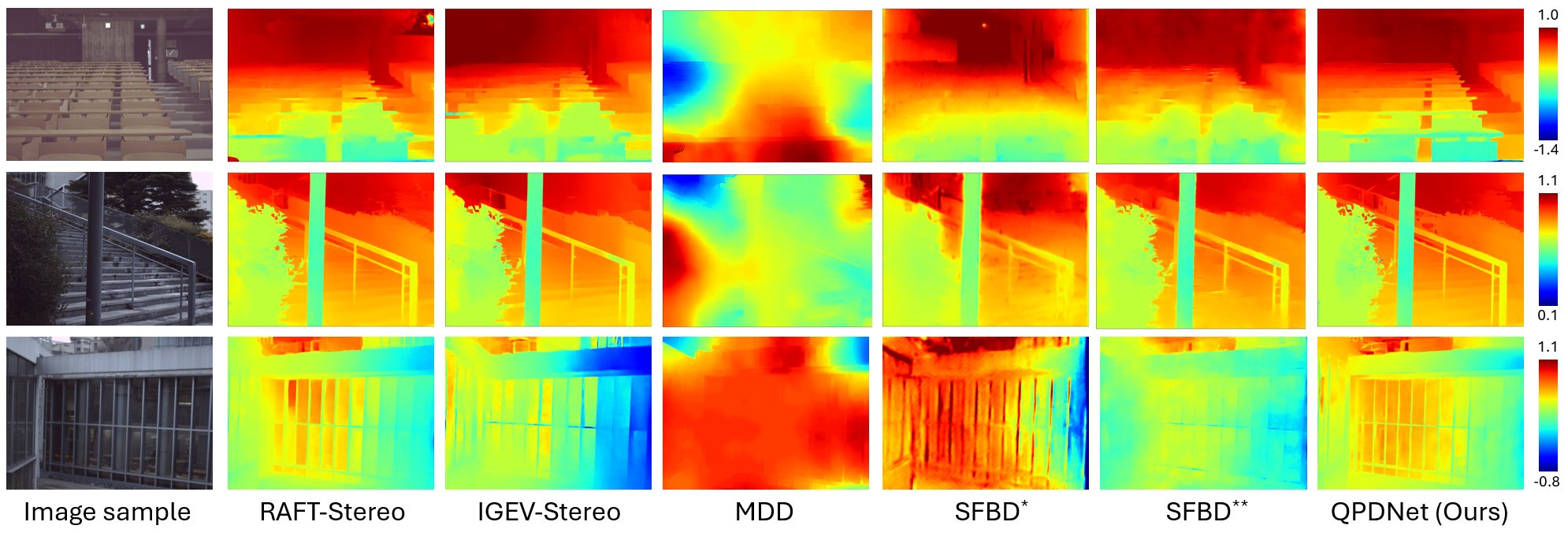
Visual comparisons on real-scene data.
Publications
Disparity Estimation Using a Quad-Pixel Sensor
Zhuofeng Wu, Doehyung Lee, Zihua Liu, Kazunori Yoshizaki, Yusuke Monno, Masatoshi Okutomi
35th British Machine Vision Conference (BMVC 2024)
Contact
Zhuofeng Wu: zwu[at]ok.sc.e.titech.ac.jp
Doehyung Lee: dlee[at]ok.sc.e.titech.ac.jp
Zihua Liu: zliu[at]ok.sc.e.titech.ac.jp
Kazunori Yoshizaki: kazunori.yoshizaki[at]olympus.com
Yusuke Monno: ymonno[at]ok.sc.e.titech.ac.jp
Masatoshi Okutomi: mxo[at]ctrl.titech.ac.jp
     |