

Abstract
Self-supervised stereo and monocular depth estimation remain limited by photometric ambiguity from missing correspondences in occluded and out-of-frame regions. We introduce DMS, a model-agnostic framework that leverages geometric priors from diffusion models to synthesize epipolar-aligned novel views via directional prompts. By fine-tuning Stable Diffusion to generate left-shifted, right-shifted, and intermediate perspectives, DMS explicitly supplements occluded pixels, providing clearer photometric supervision. Without extra labels or training cost, DMS improves self-supervised depth learning and achieves up to 35% fewer outliers across multiple benchmarks.
Method Overview
Two-Stage Training pipeline for Self-Supervised Depth Estimation using Diffusion Models.
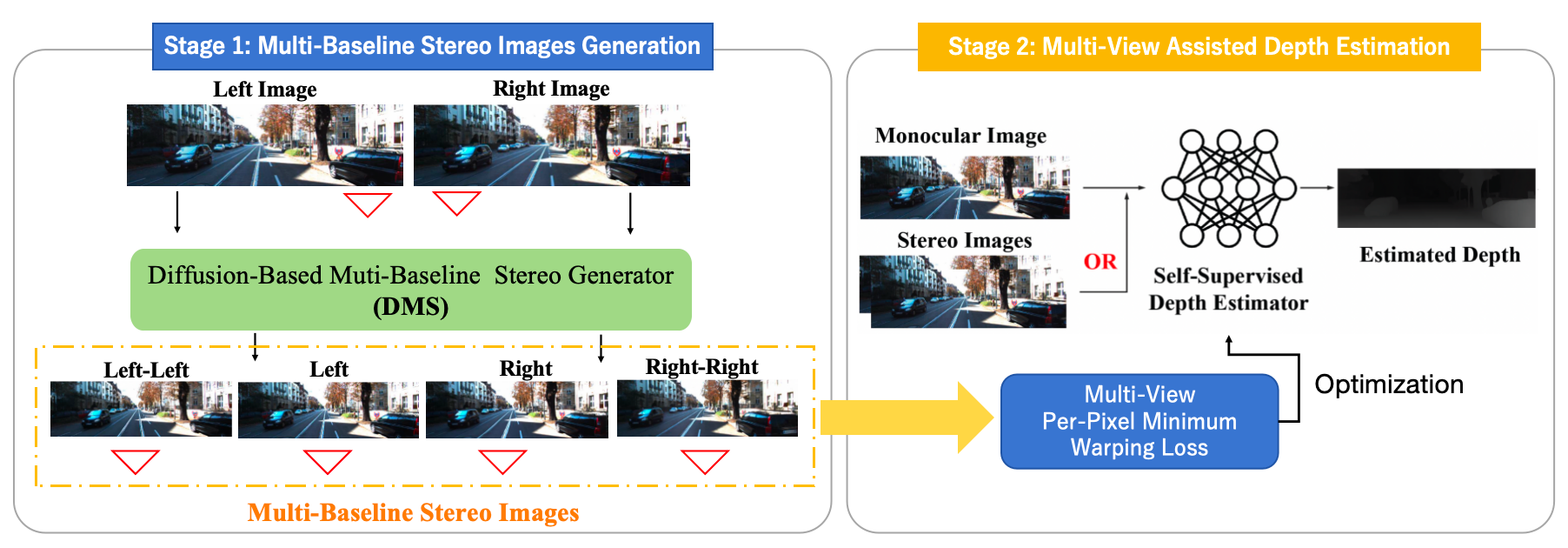
Stage 1: Start from given views, using diffusion model to generated multi-baseline images.
Stage 2: Use multi-baseline images to provide extra geometry clues to assist the self-supervised depth estimation
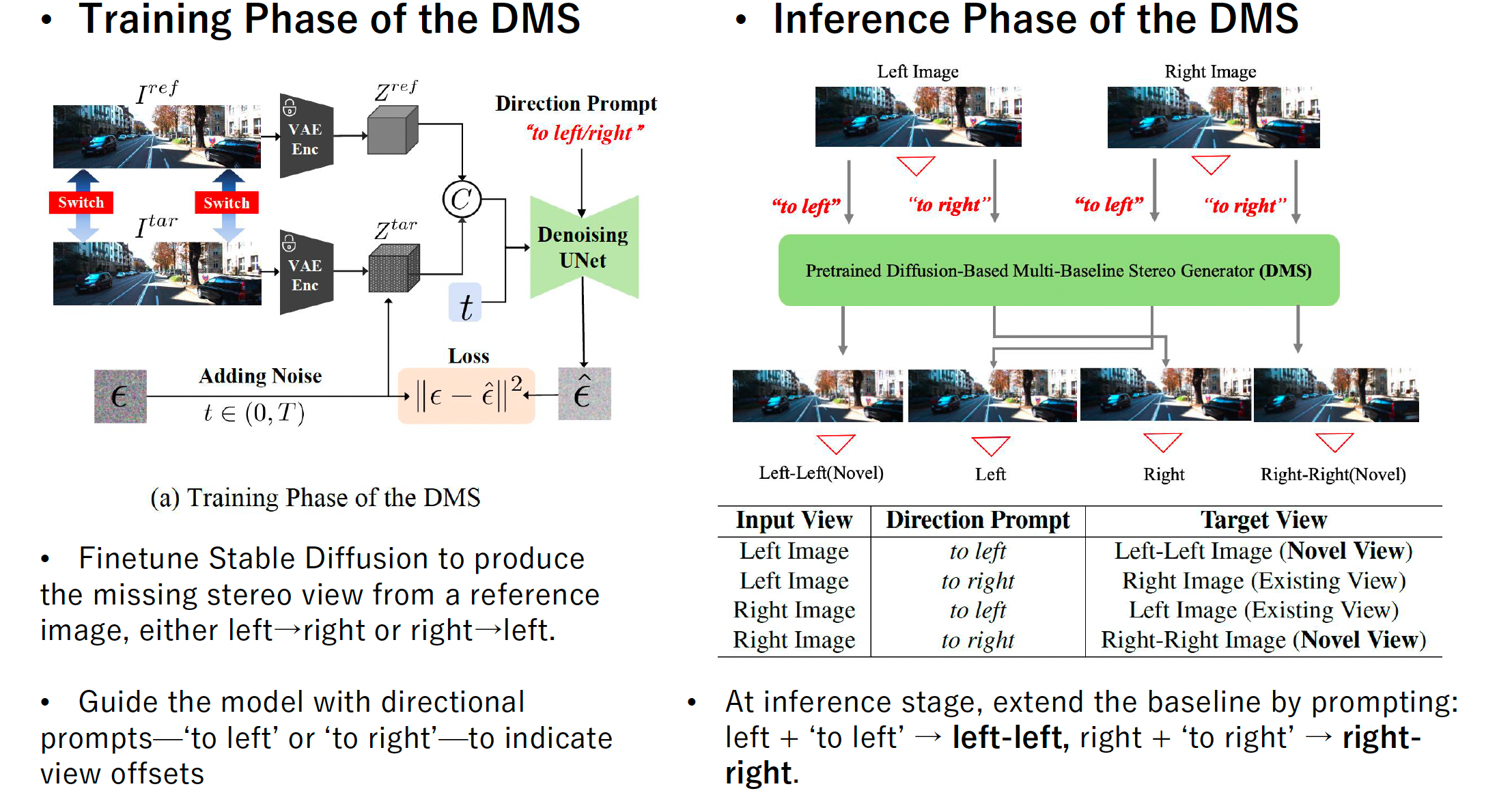
Network Achitecture Of DMS
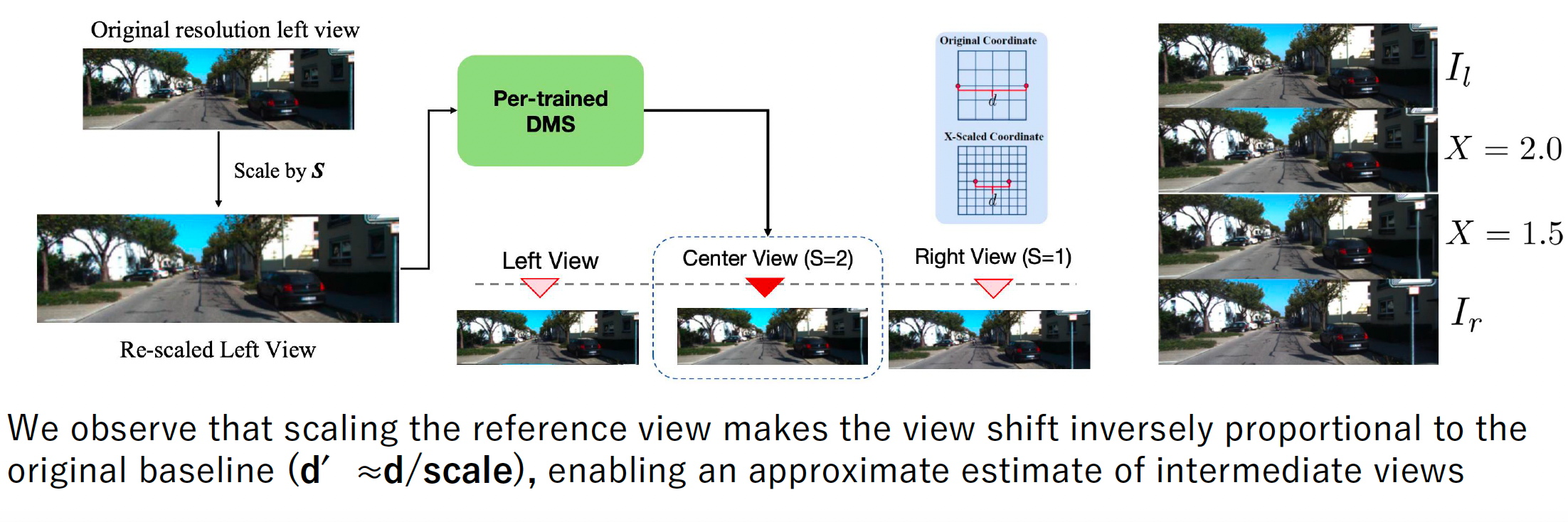
Intermediate View Approximation
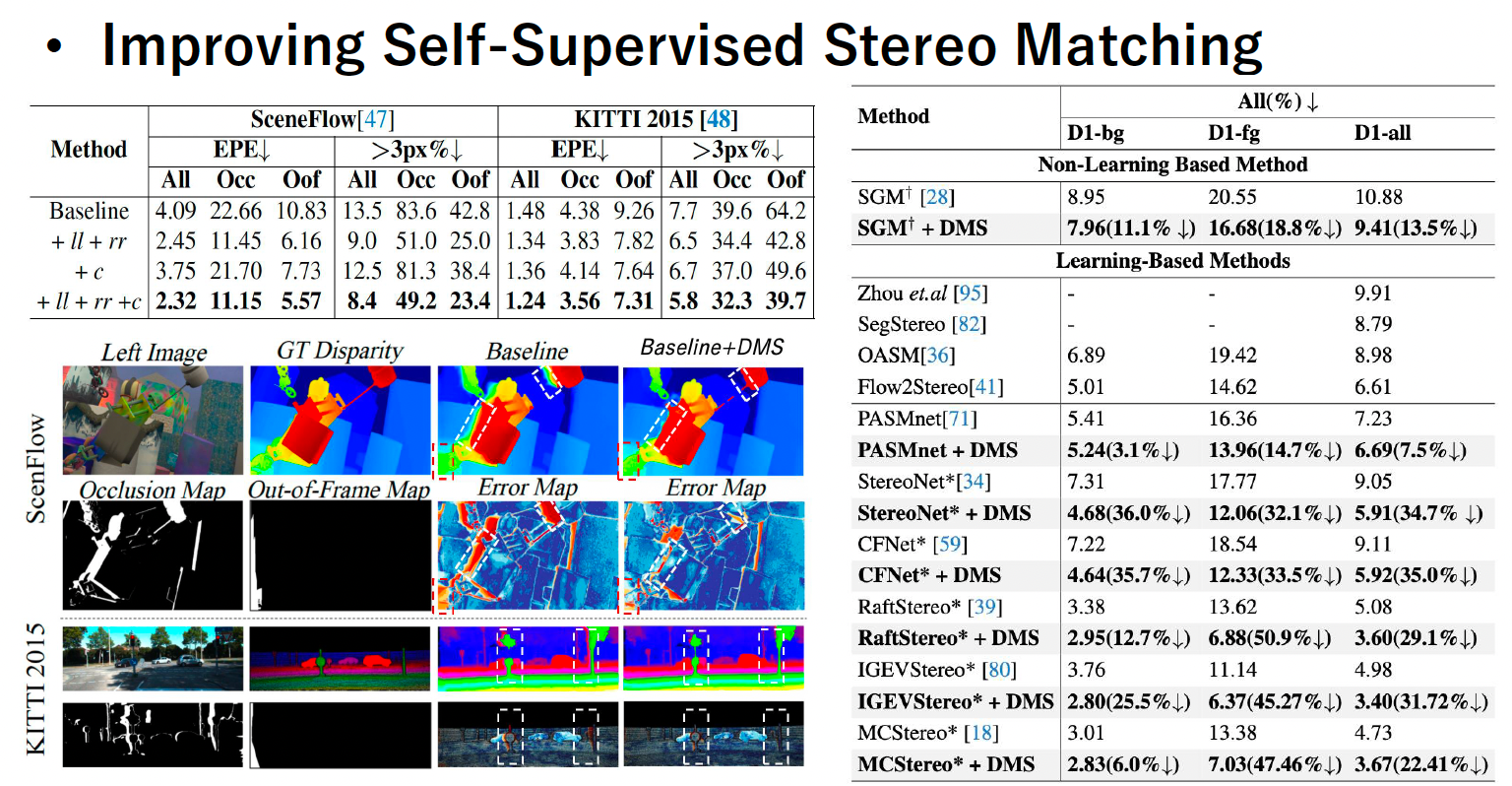
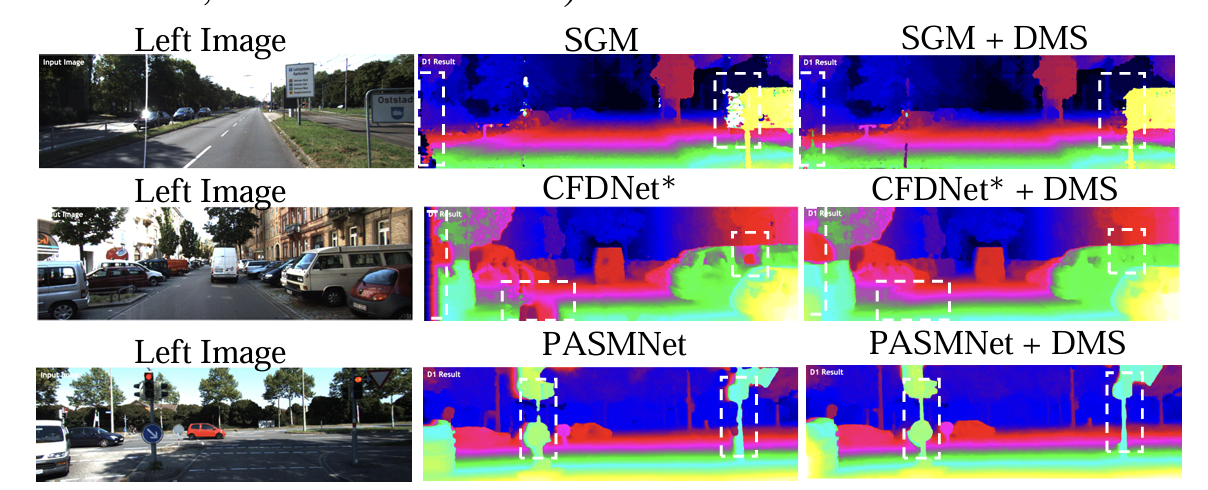
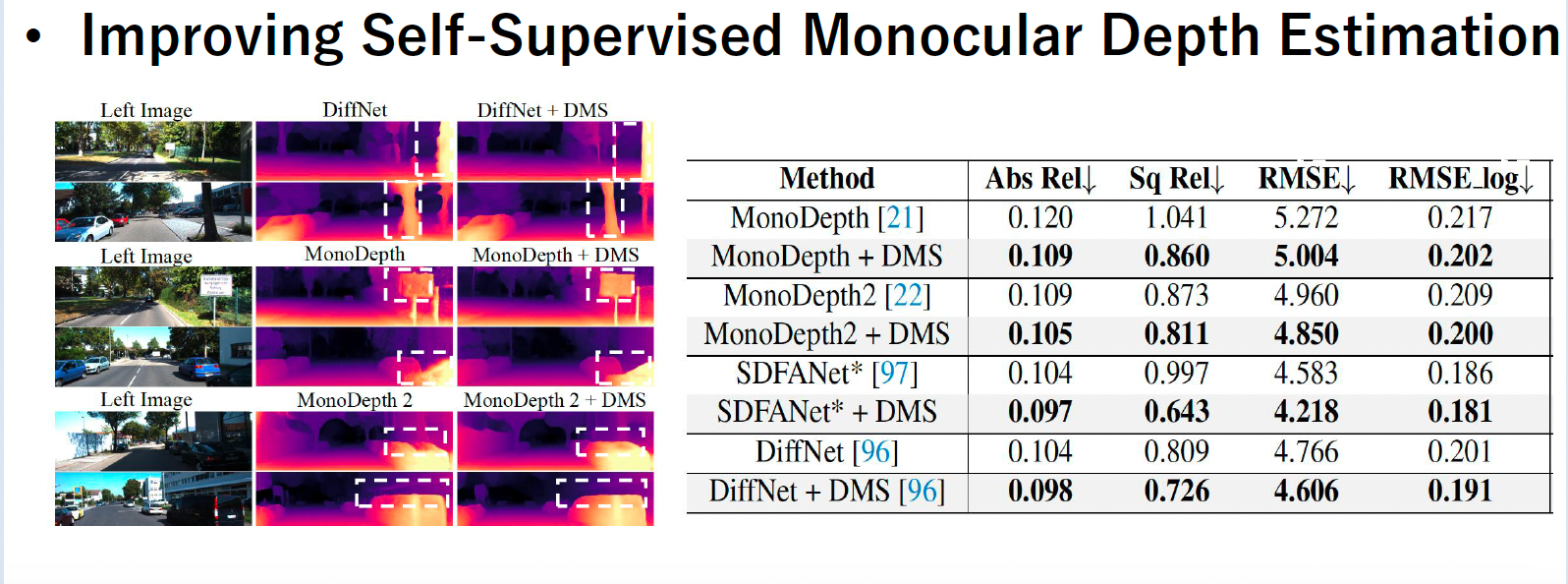
Experimental Results


Poster
BibTeX
@article{liu2025dms,
title={DMS: Diffusion-Based Multi-Baseline Stereo Generation for Improving Self-Supervised Depth Estimation},
author={Liu, Zihua and Li, Yizhou and Zhang, Songyan and Okutomi, Masatoshi},
journal={arXiv preprint arXiv:2508.13091},
year={2025}
}