Aberration-Aware Depth-from-Defocus
Okutomi-Tanaka Lab.
Tokyo Institute of Technology
Abstract
Image-based depth estimation is one of the important tasks in computer vision. Depth-from-defocus (DfD) methods estimate the scene depth from single or multiple defocused images by exploiting depth-dependent defocus blur cues. Because of the difficulty in obtaining a real-world dataset with ground-truth scene depth, most deep-learning-based DfD methods rely on a synthetic training dataset, while the generation is always time-consuming and the blur rendered may not close to real or cannot be controlled freely. Furthermore, commonly used assumption that the blur at different image positions is the same limits the performance from synthetic to real. In this paper, to address the task of aberration-aware depth-from-defocus (DfD), which takes account of spatially variant point spread functions (PSFs) of a real camera. We propose a novel self-supervised learning method that only leverages the pair of real sharp and blurred images without requiring any ground-truth PSFs, which can be easily captured by changing the aperture setting of the camera. We then design a very simple and fast synthetic training data generation method for DfD using only two front-parallel texture planes in one scene. Experimental results on spatially variant PSFs estimation demonstrate the effectiveness of our method regarding both the PSF estimation and the aberration-aware depth-from-defocus.
Method Overview
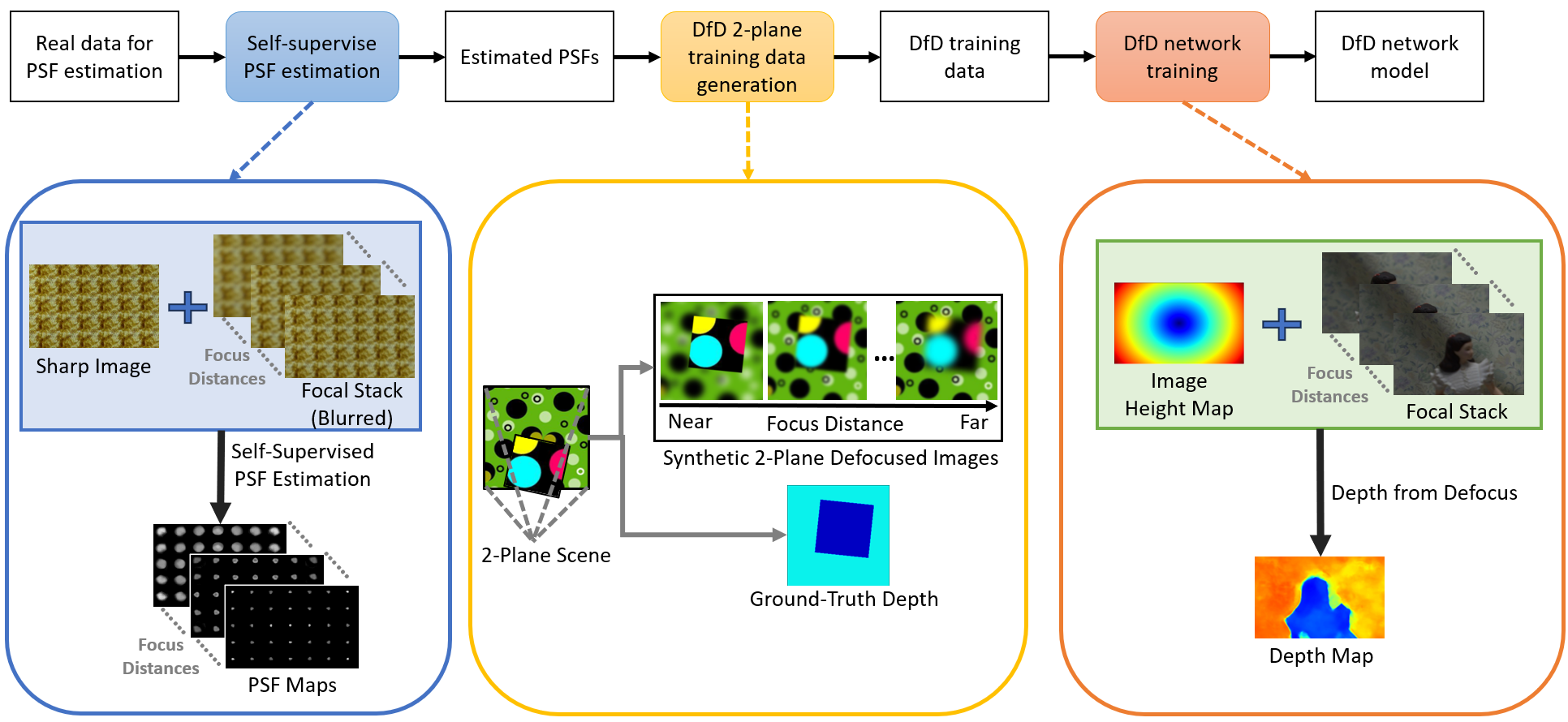
In this paper, we capture data from a real camera for PSF estimation and train our self-supervised PSF estimation network for obtain the real camera's PSFs. Next, utilizing the estimated PSF, we generate training data for Depth from Defocus (DfD) from the proposed 2-plane synthesis data generation method. Finally, we train the DfD network using the generated DfD training data.
Self-supervised PSF-Net
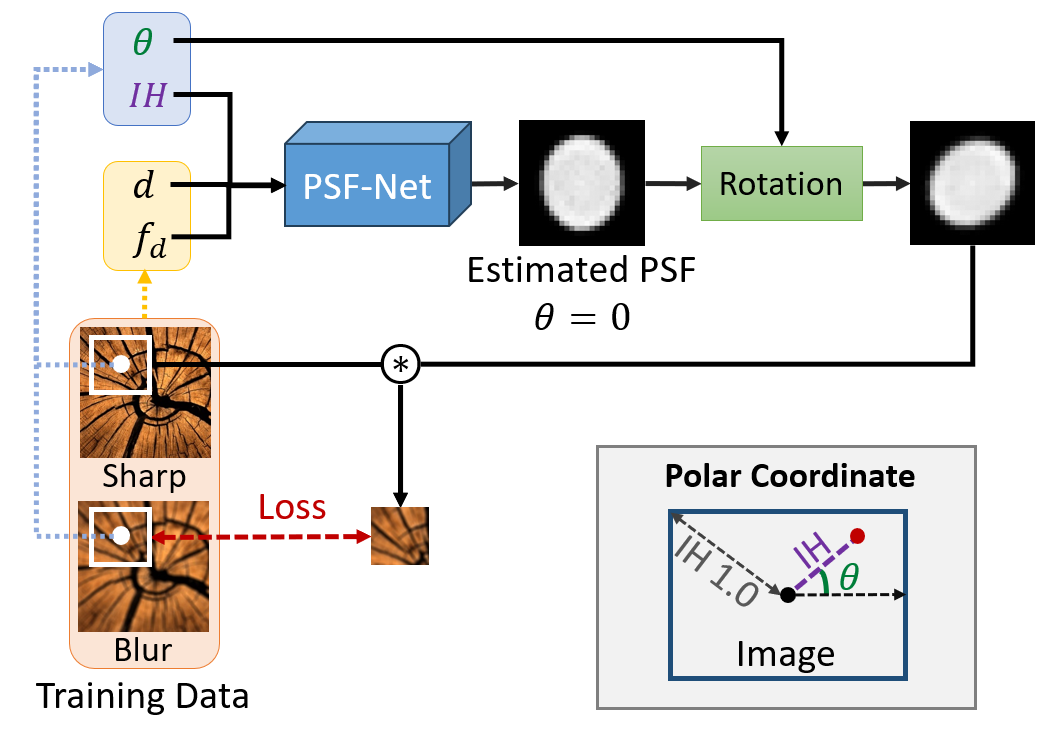
For training a PSF estimation network (PSF-Net), we leverage the pair of real sharp and real blurred images can be conveniently captured using a real camera by adjusting the aperture size and thus without requiring ground-truth PSFs.
2-Plane Defocused Image Generation
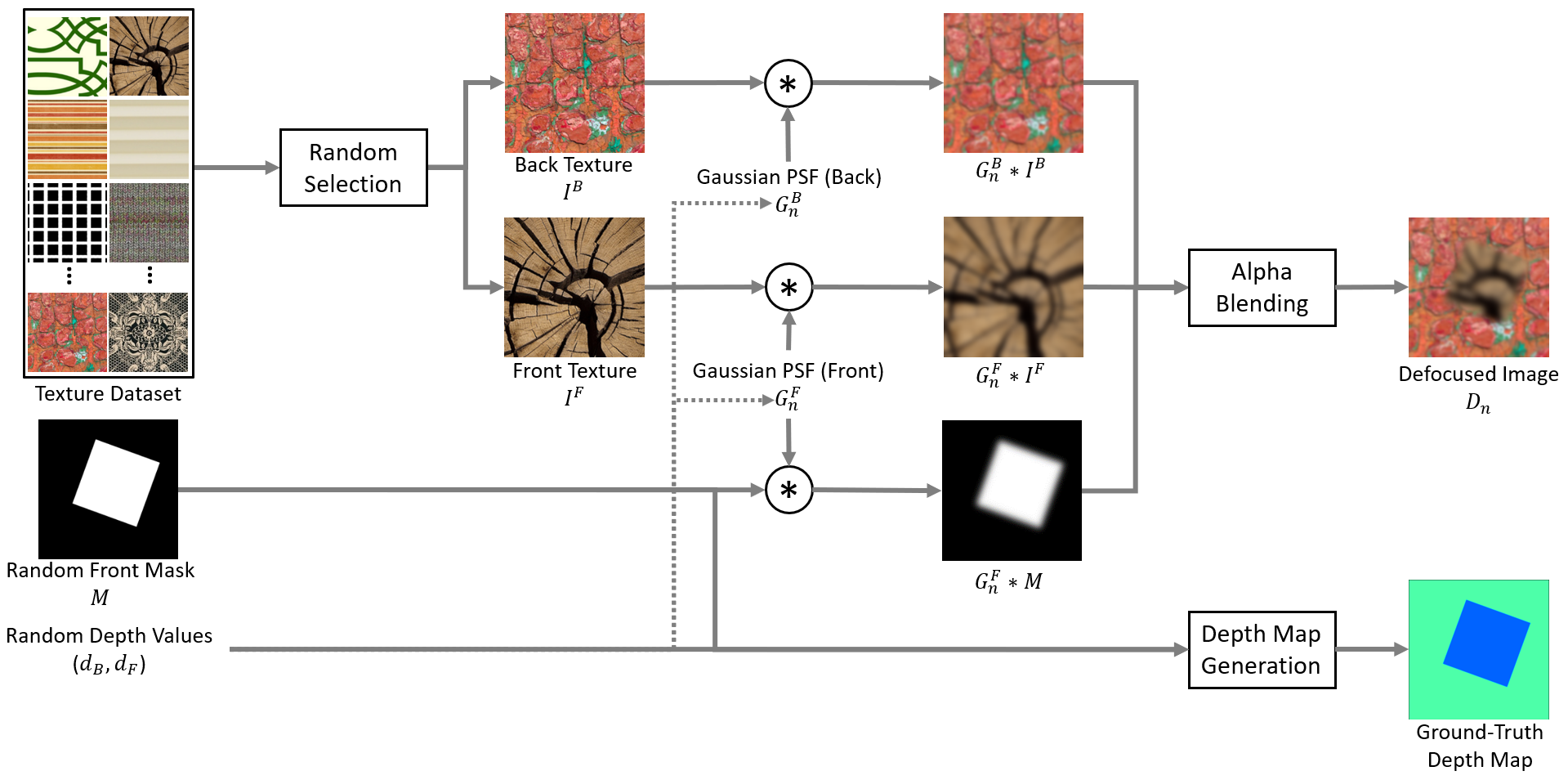
The 2-plane method requires only two front-parallel texture planes, allowing for simple, fast and accurate generation of Depth-from-Defocus training data.
Our Results on PSF Estimation

Visual comparison of the PSF estimation results (╬Ė = 45ŌŚ”) on synthetic data.
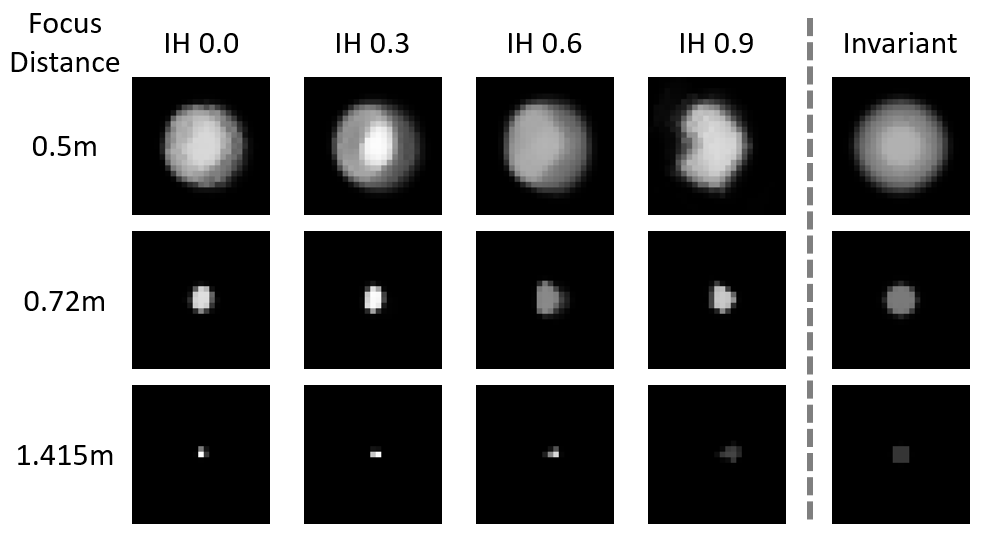
PSF estimation results (╬Ė = 0ŌŚ”) using a real Olympus camera for the depth of 1.0 meters.
Our Results on Depth Estimation
Quantitative evaluations on real one-plane data.


Depth estimation results on two real scenes.
Publications
Are Realistic Training Data Necessary for Depth-from-Defocus Networks?
Zhuofeng Wu, Yusuke Monno, Masatoshi Okutomi
48th Annual Conference of the IEEE Industrial Electronics Society (IECON 2022)
Self-supervised Spatially Variant PSF Estimation for Aberration-aware Depth-from-Defocus
Zhuofeng Wu, Yusuke Monno, Masatoshi Okutomi
2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024, accepted)
Contact
Zhuofeng Wu: zwu[at]ok.sc.e.titech.ac.jp
Yusuke Monno: ymonno[at]ok.sc.e.titech.ac.jp
Masatoshi Okutomi: mxo[at]ctrl.titech.ac.jp
     |