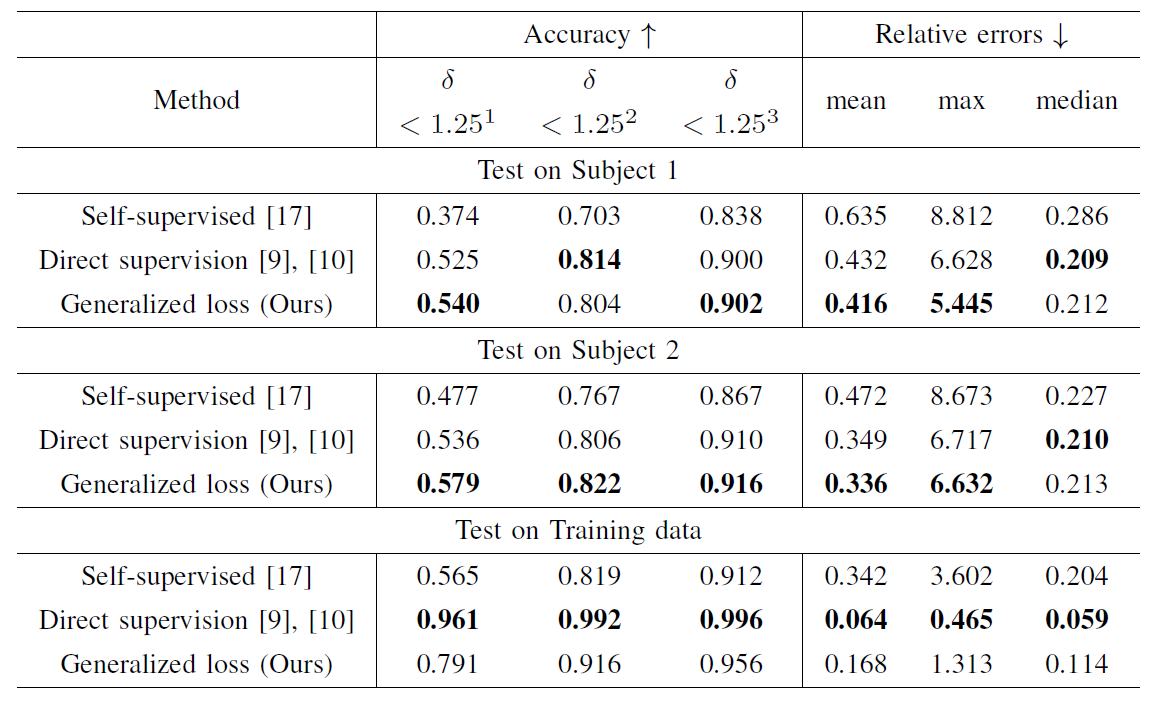
Loss function comparison
Firstly, here we introduce the network structure and three training methods that could possibly be used to train the said networks.
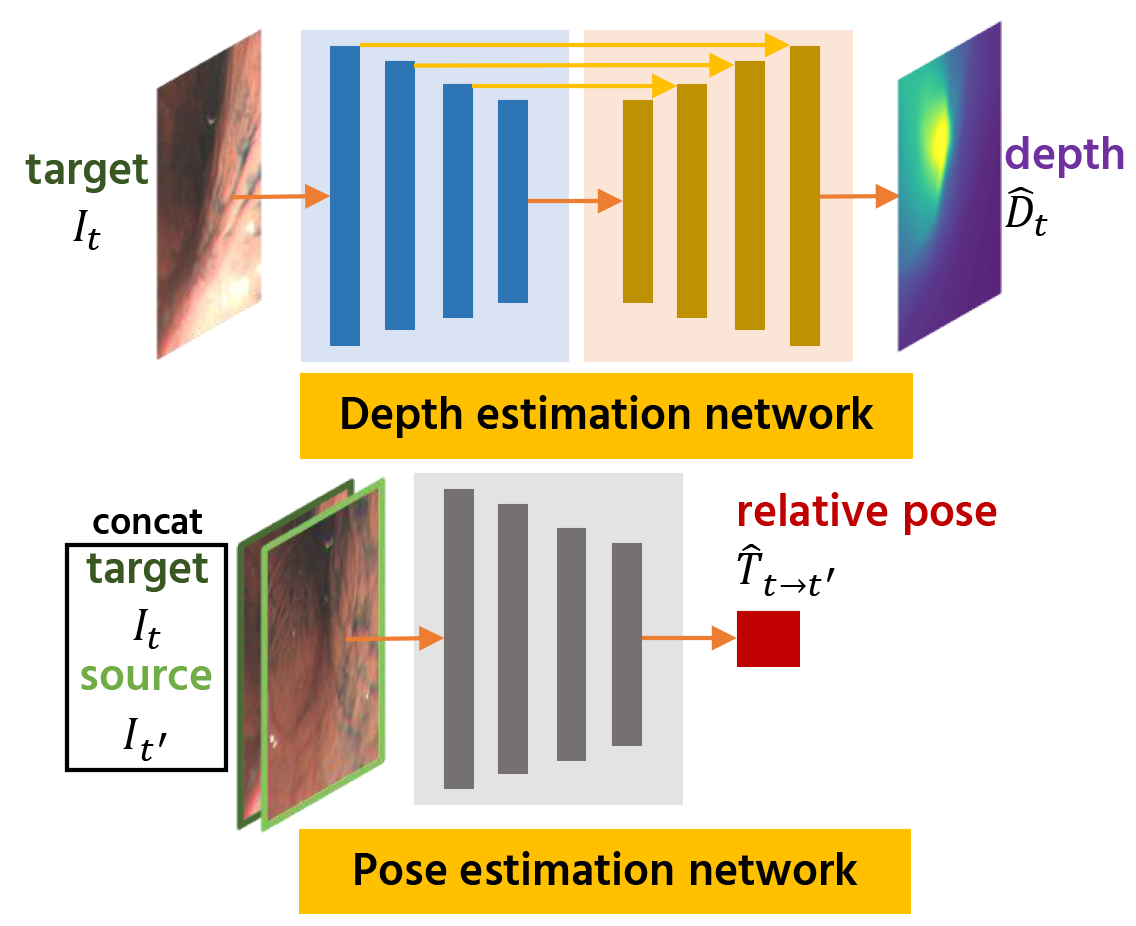 (a) Network structure, consisting of depth and pose estimation network.
(a) Network structure, consisting of depth and pose estimation network.
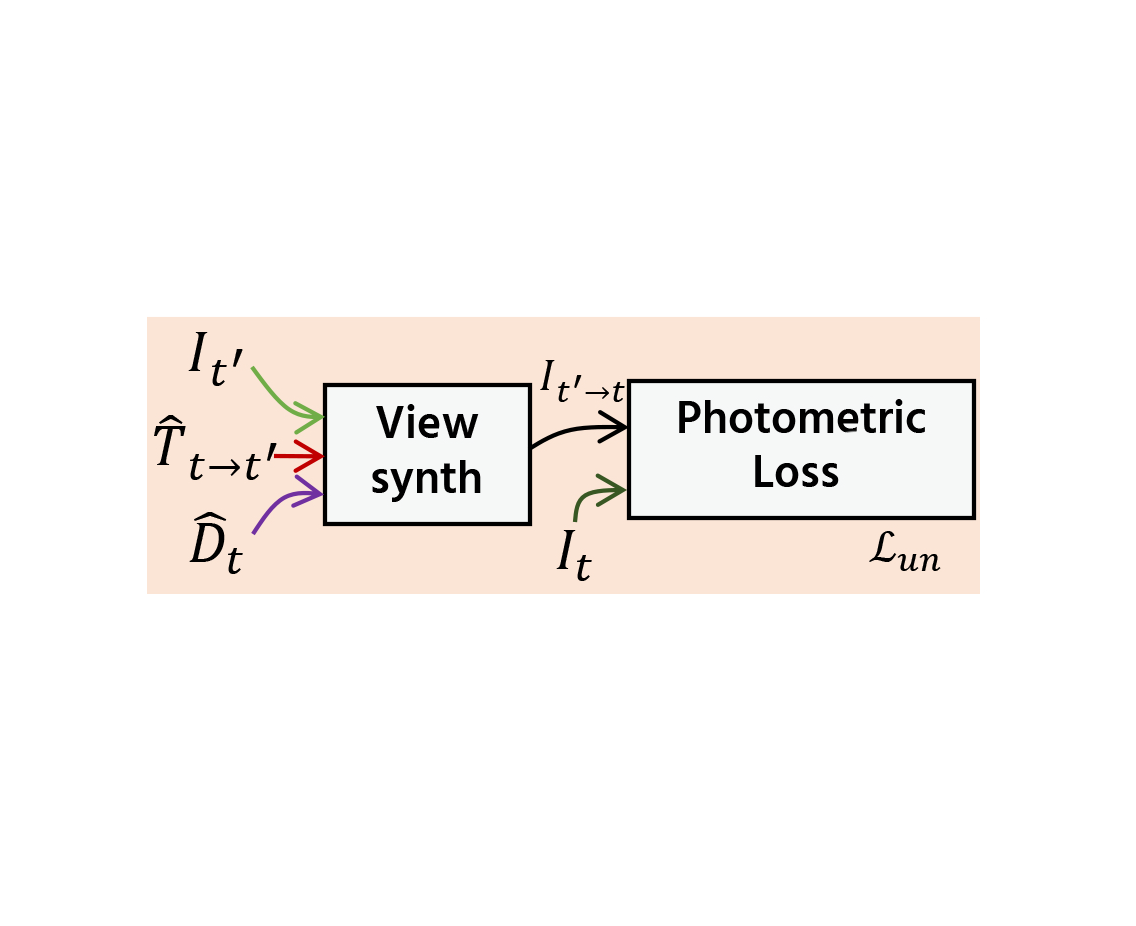 (b) Self-supervised photometric loss.
(b) Self-supervised photometric loss.
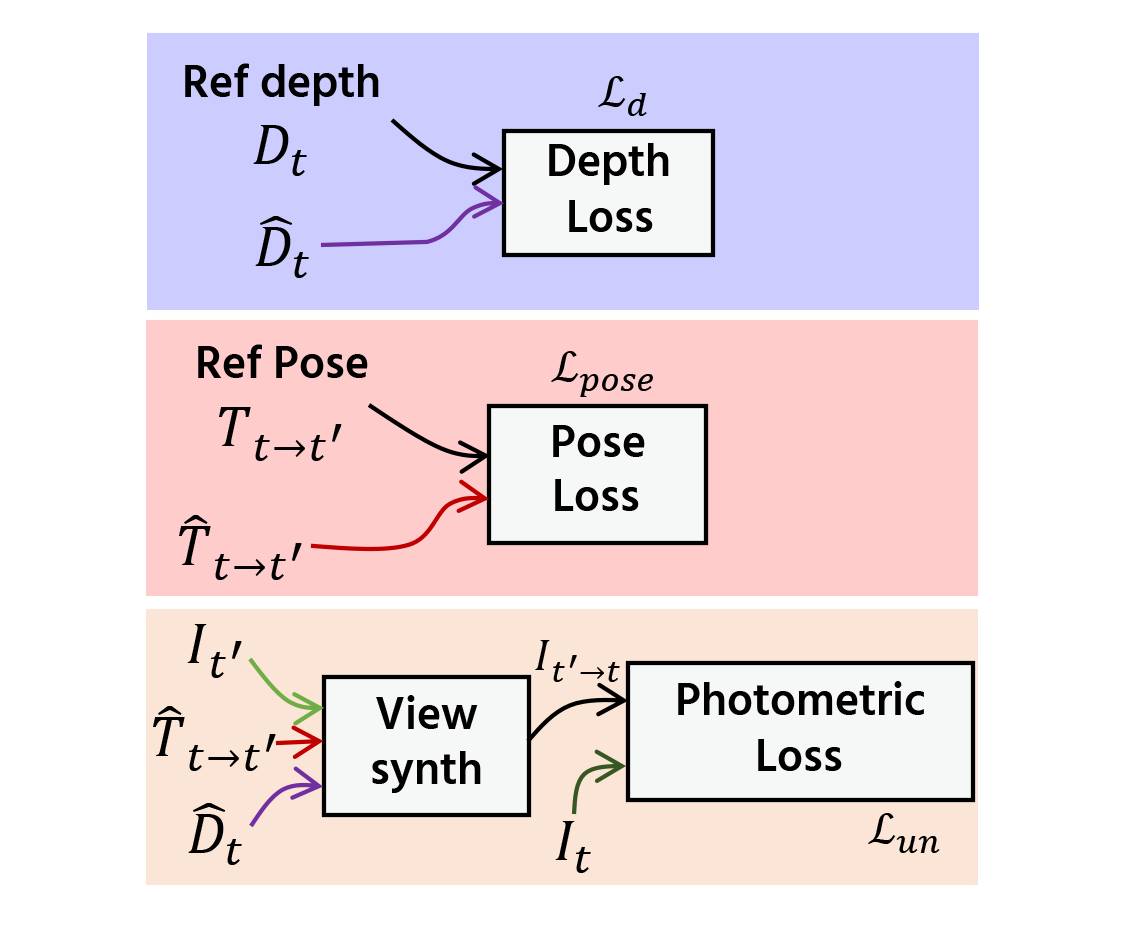 (c) Commonly used direct depth and pose supervision loss.
(c) Commonly used direct depth and pose supervision loss.
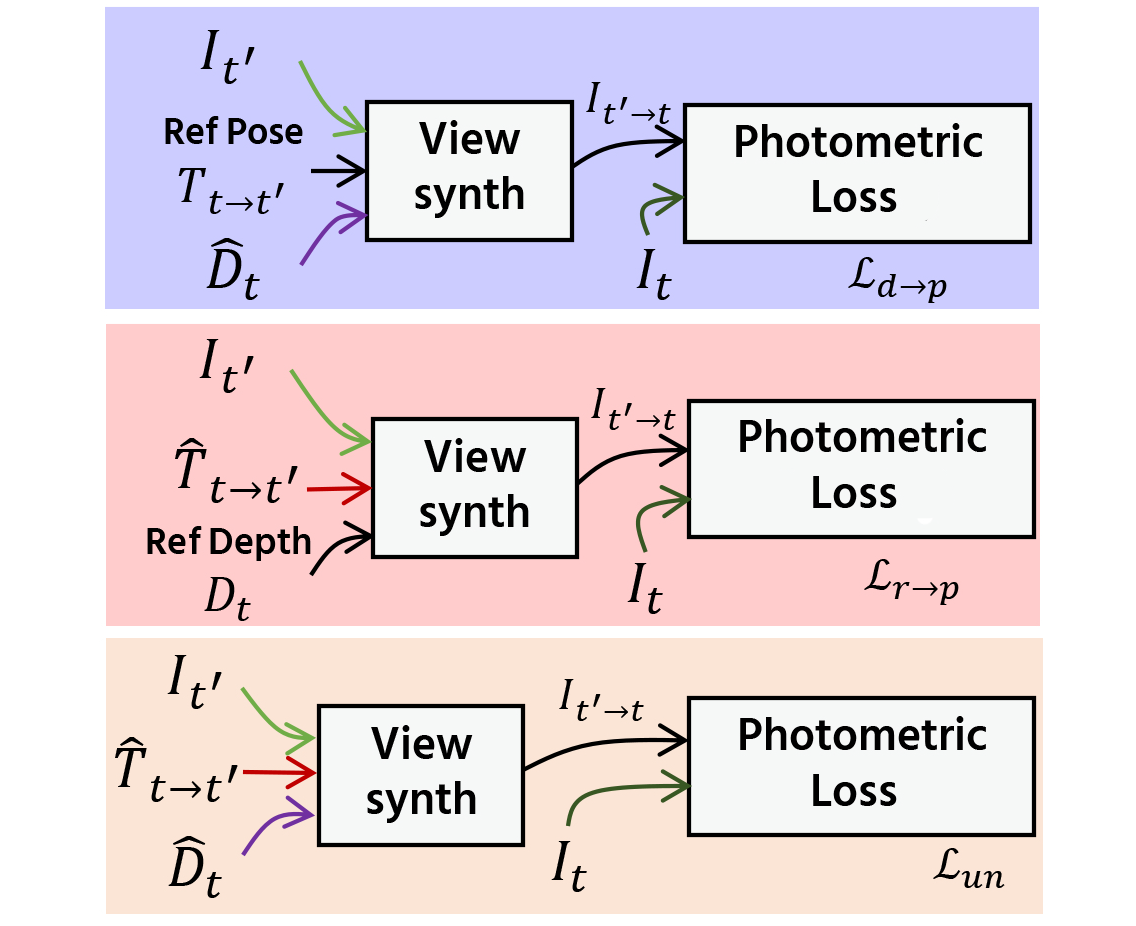 (d) Proposed generalized photometric loss.
(d) Proposed generalized photometric loss.
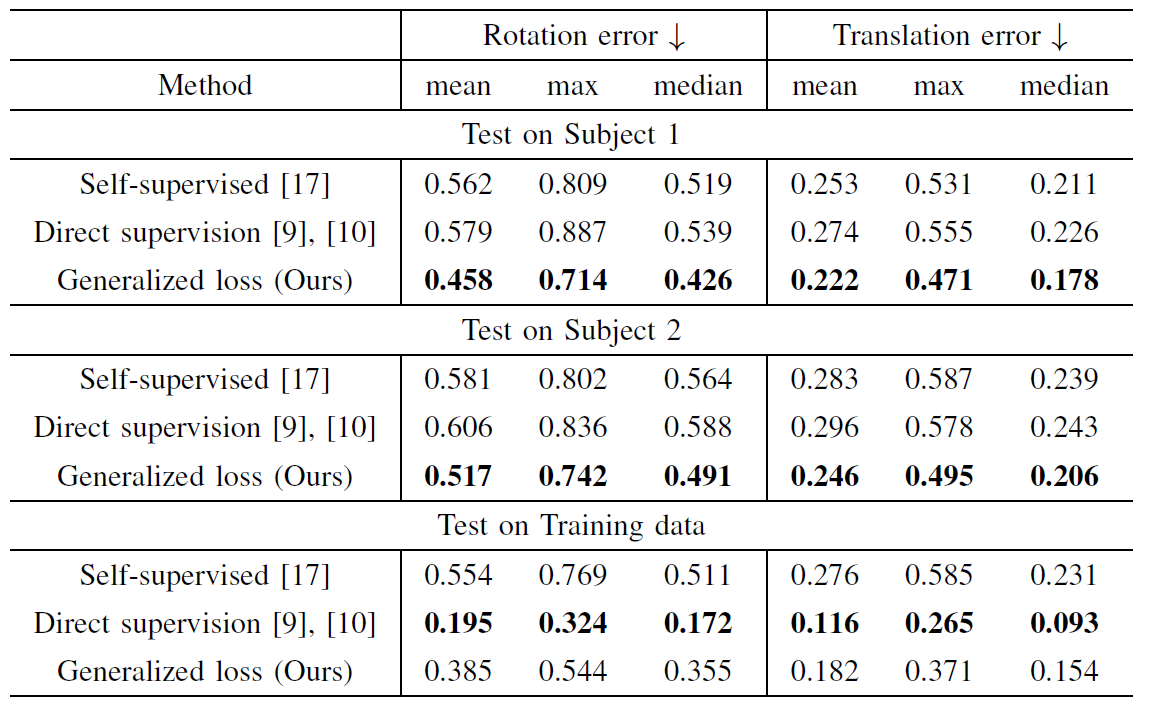
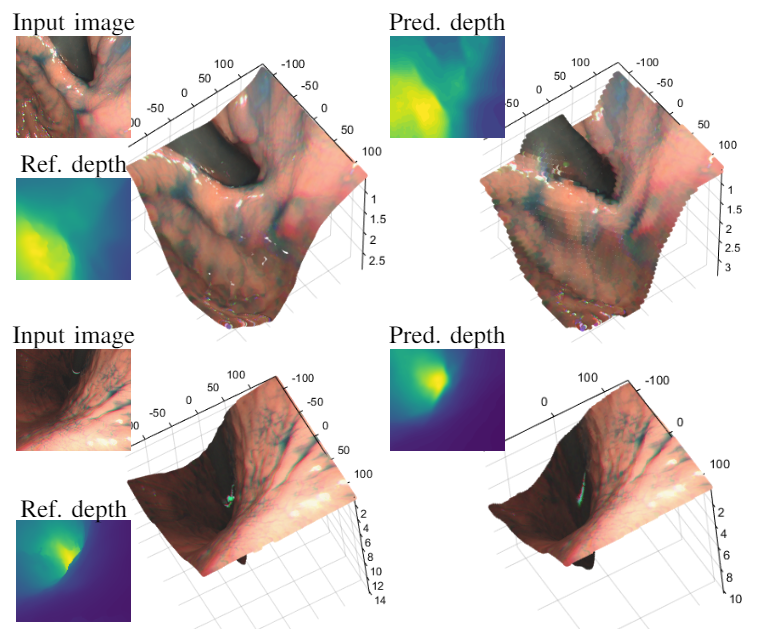
The network structure which consists of depth and pose estimation networks is shown in (a). Figures (b)-(d) show the comparison between the existing self-supervised photometric loss, the existing direct depth and pose supervision loss, and our proposed generalized photometric loss. In both (c) and (d), the loss in the purple-colored box is used for training the depth estimation network and the loss in the pink-colored box is used for training the pose estimation network. The existing depth and pose supervision approach trains the depth and the pose estimation networks by directly taking the Euclidean distance between the predicted depth and its reference and also between the predicted pose and its reference, respectively. This direct supervision approach needs balancing the weights for each loss term, which are difficult to search, because their physical meanings are different. In our proposed generalize loss, we adjusted our loss terms so that each of them has the same physical meaning, i.e., the photometric error. This generalization eliminates the need for the balancing weight search.
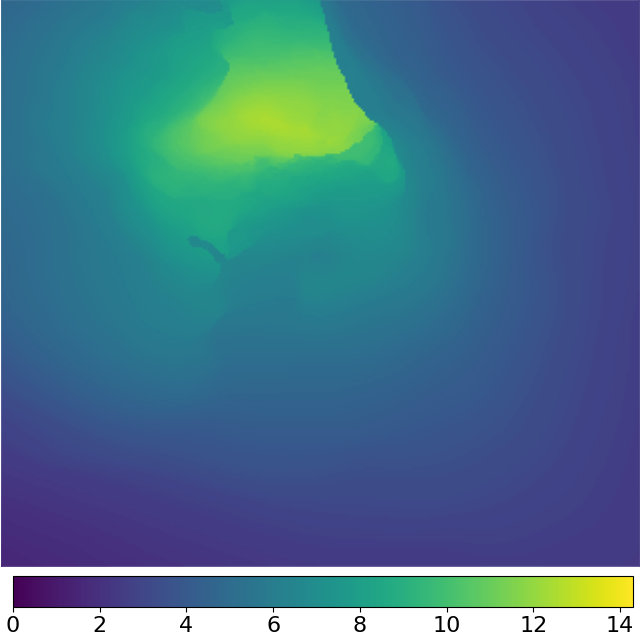
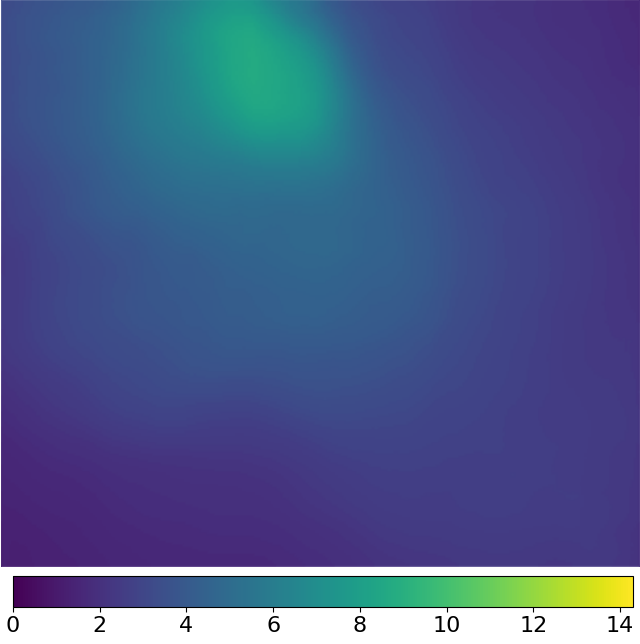
 (a)
(a)
 (b)
(b)