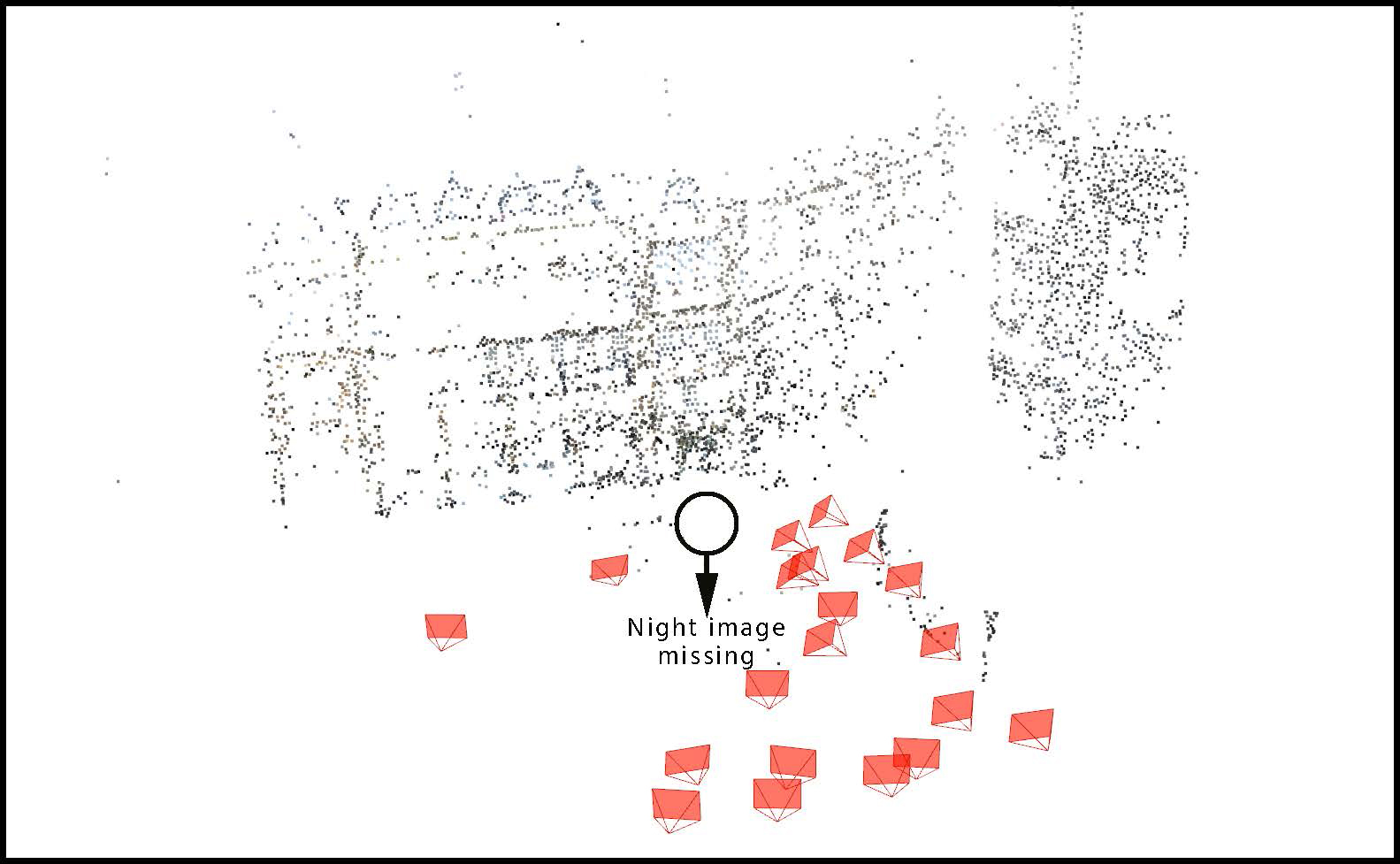
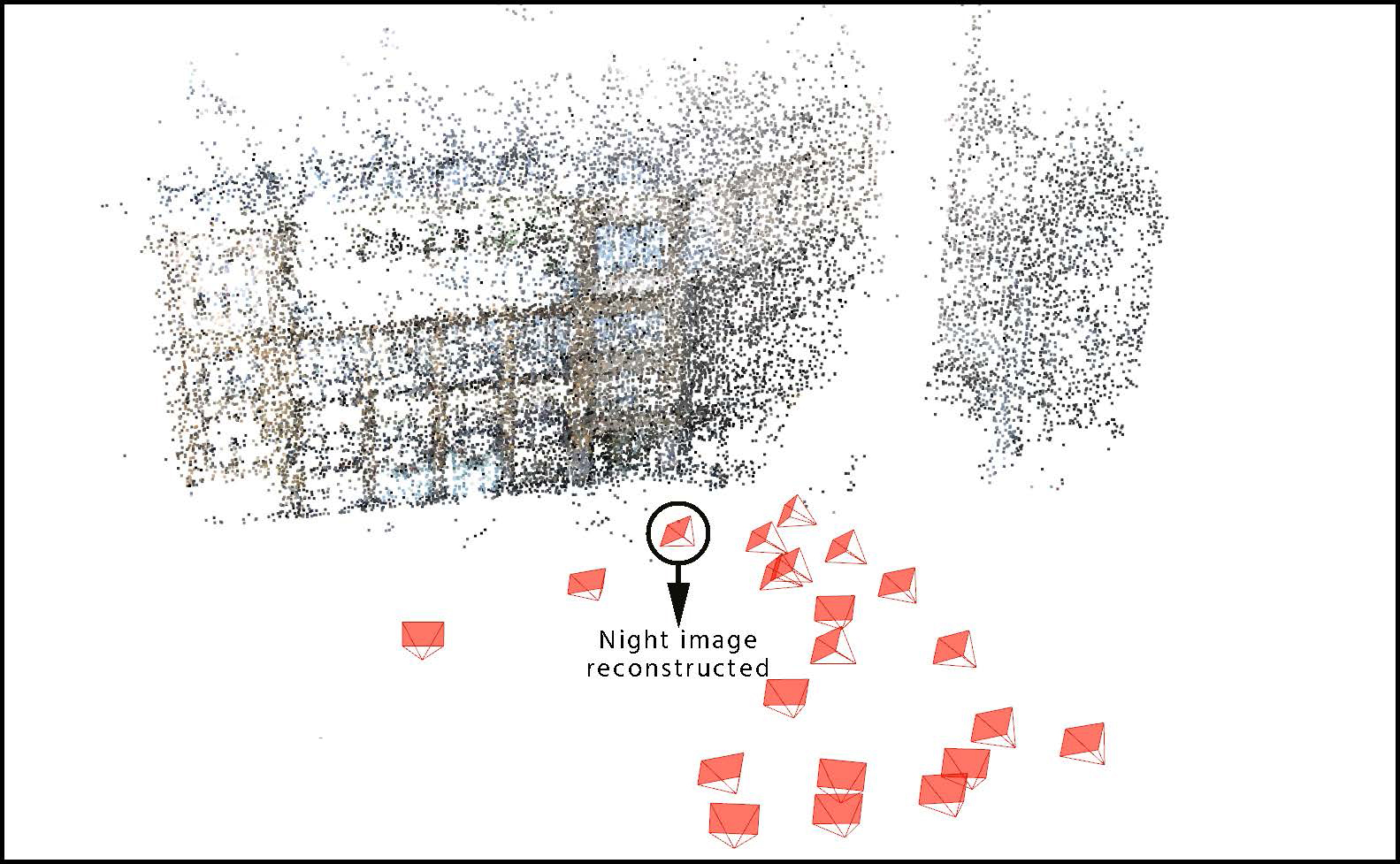
Summary
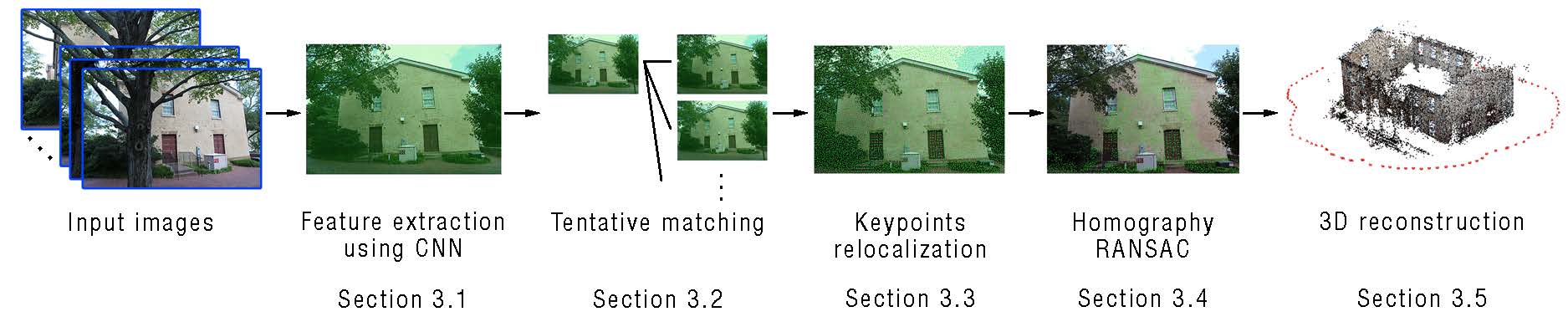
Based on the figure above, our algorithm works as follow:
Densely extract the feature from each of input image using convolutional neural network (CNN). We use pre-trained VGG-16 in our implementation.
Do tentative matching. Compute the nearest neighbour to find matches between keypoint.
Relocalize keypoints since the accuracy of densely extracted keypoints are still not in pixel-level accuracy.
Do Homography RANSAC to remove outlier keypoint matches.
Do final 3D reconstruction using any 3D reconstruction pipeline.