Publication
Conference paper
Automatic Labeled LiDAR Data Generation based on Precise Human Model (paper) (code & data)
Wonjik Kim , Masayuki Tanaka, Masatoshi Okutomi, Yoko Sasaki
International Conference on Robotics and Automation (ICRA), 2019.
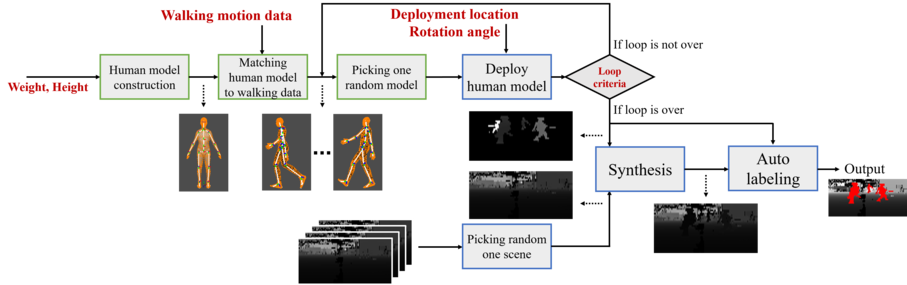
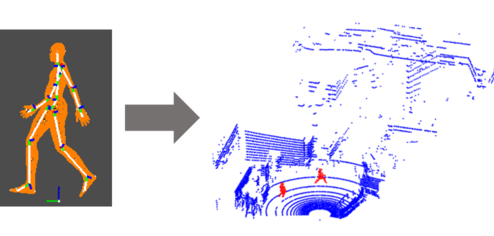
Following improvements in deep neural networks, state-of-the-art networks have been proposed for human recog- nition using point clouds captured by LiDAR. However, the performance of these networks strongly depends on the training data. An issue with collecting training data is labeling. Labeling by humans is necessary to obtain the ground truth label; however, labeling requires huge costs. Therefore, we propose an automatic labeled data generation pipeline, for which we can change any parameters or data generation environments. Our approach uses a human model named Dhaiba and a background of the Miraikan and consequently generated re- alistic artificial data. We present 400k+ data generated by the proposed pipeline. This paper also describes the specification of the pipeline and data details with evaluations of various approaches.
Human Segmentation with Dynamic LiDAR Data (paper) (code)
Tao Zhong, Wonjik Kim , Masayuki Tanaka, Masatoshi Okutomi
International Conference on Pattern Recognition (ICPR), 2020.
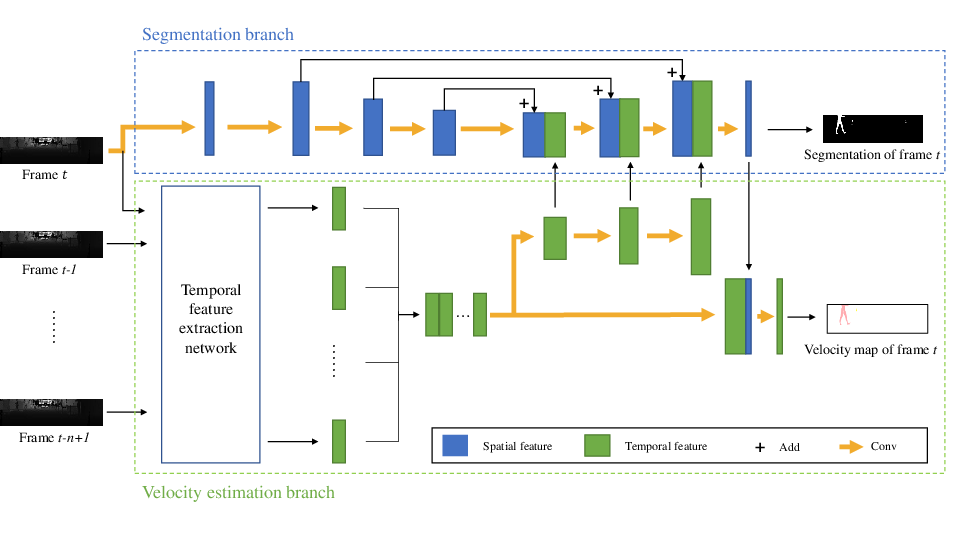
Consecutive LiDAR scans compose dynamic 3D sequences, which contain more abundant information than a single frame. Similar to the development history of image and video perception, dynamic 3D sequence perception starts to come into sight after inspiring research on static 3D data perception. This work proposes a spatio-temporal neural network for human segmentation with the dynamic LiDAR point clouds. It takes a sequence of depth images as input. It has a two-branch structure, i.e., the spatial segmentation branch and the temporal velocity estimation branch. The velocity estimation branch is designed to capture motion cues from the input sequence and then propagates them to the other branch. So that the segmentation branch segments humans according to both spatial and temporal features. These two branches are jointly learned on a generated dynamic point cloud dataset for human recognition. Our works fill in the blank of dynamic point cloud perception with the spherical representation of point cloud and achieves high accuracy. The experiments indicate that the introduction of temporal feature benefits the segmentation of dynamic point cloud.
Journal paper
Automatic Labeled LiDAR Data Generation and Distance-Based Ensemble Learning for Human Segmentation (paper) (code & data)
Wonjik Kim , Masayuki Tanaka, Masatoshi Okutomi, Yoko Sasaki
IEEE Access, 2019.
Following the improvements in deep neural networks, state-of-the-art networks have been proposed for human segmentation using point clouds captured by light detection and ranging. However, the performance of these networks depends significantly on the training data. An issue with collecting training data is labeling. Labeling by humans is necessary to obtain ground-truth labels; however, labeling involves high costs. Therefore, we propose an automatically labeled data generation pipeline, for which we can change any parameters or data generation environments. Our approach uses a human model named Dhaiba and the background of Miraikan to generate realistic artificial data. We present 1M data generated by the proposed pipeline. Furthermore, we propose an ensemble learning based on generated data for utilizing our data generation pipeline. This paper proposes the specifications of the pipeline, data details, and explanation of ensemble learning with evaluations of various approaches.
Learning-Based Human Segmentation and Velocity Estimation Using Automatic Labeled LiDAR Sequence for Training (paper) (code & data)
Wonjik Kim , Masayuki Tanaka, Masatoshi Okutomi, Yoko Sasaki
IEEE Access, 2020.
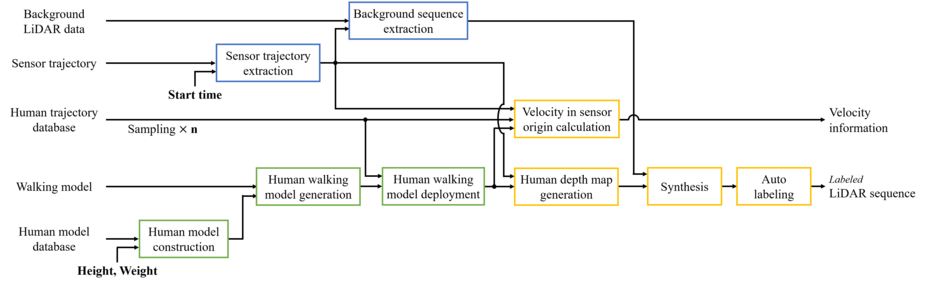
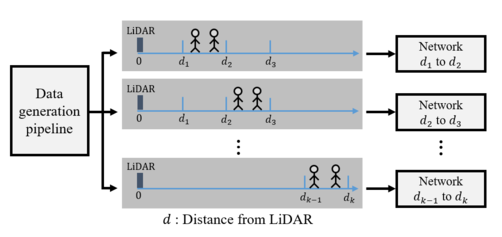
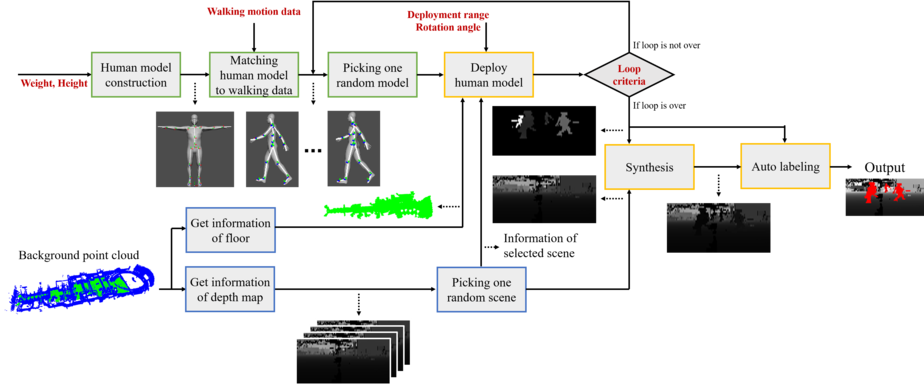
In this paper, we propose an automatic labeled sequential data generation pipeline for human segmentation and velocity estimation with point clouds. Considering the impact of deep neural networks, state-of-the-art network architectures have been proposed for human recognition using point clouds captured by Light Detection and Ranging (LiDAR). However, one disadvantage is that legacy datasets may only cover the image domain without providing important label information and this limitation has disturbed the progress of research to date. Therefore, we develop an automatic labeled sequential data generation pipeline, in which we can control any parameter or data generation environment with pixel-wise and per-frame ground truth segmentation and pixel-wise velocity information for human recognition. Our approach uses a precise human model and reproduces a precise motion to generate realistic artificial data. We present more than 7K video sequences which consist of 32 frames generated by the proposed pipeline. With the proposed sequence generator, we confirm that human segmentation performance is improved when using the video domain compared to when using the image domain. We also evaluate our data by comparing with data generated under different conditions. In addition, we estimate pedestrian velocity with LiDAR by only utilizing data generated by the proposed pipeline.